공모전 준비를 위해 작성했던 크롤링 코드를 정리하는 글입니다.
크롤링은 공공데이터포털에서 전국 숙박업소에 대한 데이터를 다운로드하여 해당 데이터에 있는 숙소명을 네이버 지도에 직접 검색하여 리뷰를 가져오는 방식으로 진행했다.
다음과 같은 데이터 df에서 '업소명' 컬럼을 사용했으며,

크롤링 과정을 간단히 작성하면 다음과 같다.
- 크롬 웹드라이버에서 해당 숙소의 고유 주소로 이동(크롤링 코드에서 고유 주소(url)가 나오니 참고)
- 해당 숙소 정보에서 리뷰 탭으로 이동 리뷰 탭으로 이동
- 방문자 리뷰 텍스트를 크롤링
먼저 webdrvier-manager를 설치한다.
pip install webdriver-manager
time 라이브러리와 warning을 무시하기 위한 라이브러리를 import 한다.
import time
import warnings
warnings.filterwarnings('ignore')
크롤링을 위해 필요한 라이브러리도 import 해준다.
동적 크롤링을 위해 selenium을 사용하였고, webdriver로는 크롬드라이버를 사용했다.
from selenium import webdriver # 동적크롤링
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
리뷰를 추출하는 함수 extract_review를 만들어주었다.
리뷰 추출 함수에서는 XPATH를 사용해 리뷰 텍스트의 위치를 찾고 추출하였다.
def extract_review():
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 리뷰 추출
rev = [] # 추출한 리뷰 저장
for i in range(1, 11): # 더보기 누르지 않은 상태로 최대 10개
try: # 사진 없는 후기는 div 3번째에 텍스트 위치
driver.find_element(By.XPATH, '//*[@id="app-root"]/div/div/div/div[7]/div[3]/div[4]/div[1]/ul/li['+str(i)+']/div[3]/a').send_keys(Keys.ENTER) # 텍스트 전체 볼 수 있게 클릭
time.sleep(2)
comment = driver.find_element(By.XPATH, '//*[@id="app-root"]/div/div/div/div[7]/div[3]/div[4]/div[1]/ul/li['+str(i)+']/div[3]/a/span').text # 리뷰
rev.append(comment)
except: # 사진 있는 후기는 div 4번째에 텍스트가 위치
driver.find_element(By.XPATH, '//*[@id="app-root"]/div/div/div/div[7]/div[3]/div[4]/div[1]/ul/li['+str(i)+']/div[4]/a').send_keys(Keys.ENTER)
time.sleep(2)
comment = driver.find_element(By.XPATH, '//*[@id="app-root"]/div/div/div/div[7]/div[3]/div[4]/div[1]/ul/li['+str(i)+']/div[4]/a/span').text # 리뷰
rev.append(comment)
return rev
각 숙소 리뷰는 data에 저장한다.
data = []
리뷰 크롤링 코드는 다음과 같다.
# 크롬 드라이버 실행
driver = webdriver.Chrome(ChromeDriverManager().install())
for i in df['업소명']:
# 검색창에 입력하지 않고 직접 해당 숙소의 주소로 이동
url = "https://map.naver.com/v5/search/전주 "+str(i)+'/place'
driver.get(url)
time.sleep(8)
try:
driver.switch_to.frame(driver.find_element(By.XPATH, '//*[@id="entryIframe"]')) # iframe 이동
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 리뷰 탭으로 이동
lists = soup.select('#app-root > div > div > div > div.place_section.OP4V8 > div.zD5Nm.f7aZ0 > div.dAsGb > span')
# 별점/방문자리뷰/블로그리뷰 순일때 방문자리뷰는 두번째에 위치=span[2]
if len(lists) > 2:
driver.find_element(By.XPATH, '//*[@id="app-root"]/div/div/div/div[2]/div[1]/div[2]/span[2]/a').send_keys(Keys.ENTER) # 방문자 리뷰
time.sleep(3)
# 방문자리뷰/블로그리뷰 순일때 방문자리뷰는 첫번째에 위치=span[1]
else:
driver.find_element(By.XPATH, '//*[@id="app-root"]/div/div/div/div[2]/div[1]/div[2]/span[1]/a').send_keys(Keys.ENTER) # 방문자 리뷰
time.sleep(3)
review = extract_review() # 리뷰 추출 함수 호출
data.append(review)
# print(review)
except:
data.append(' ')
# print(' ')
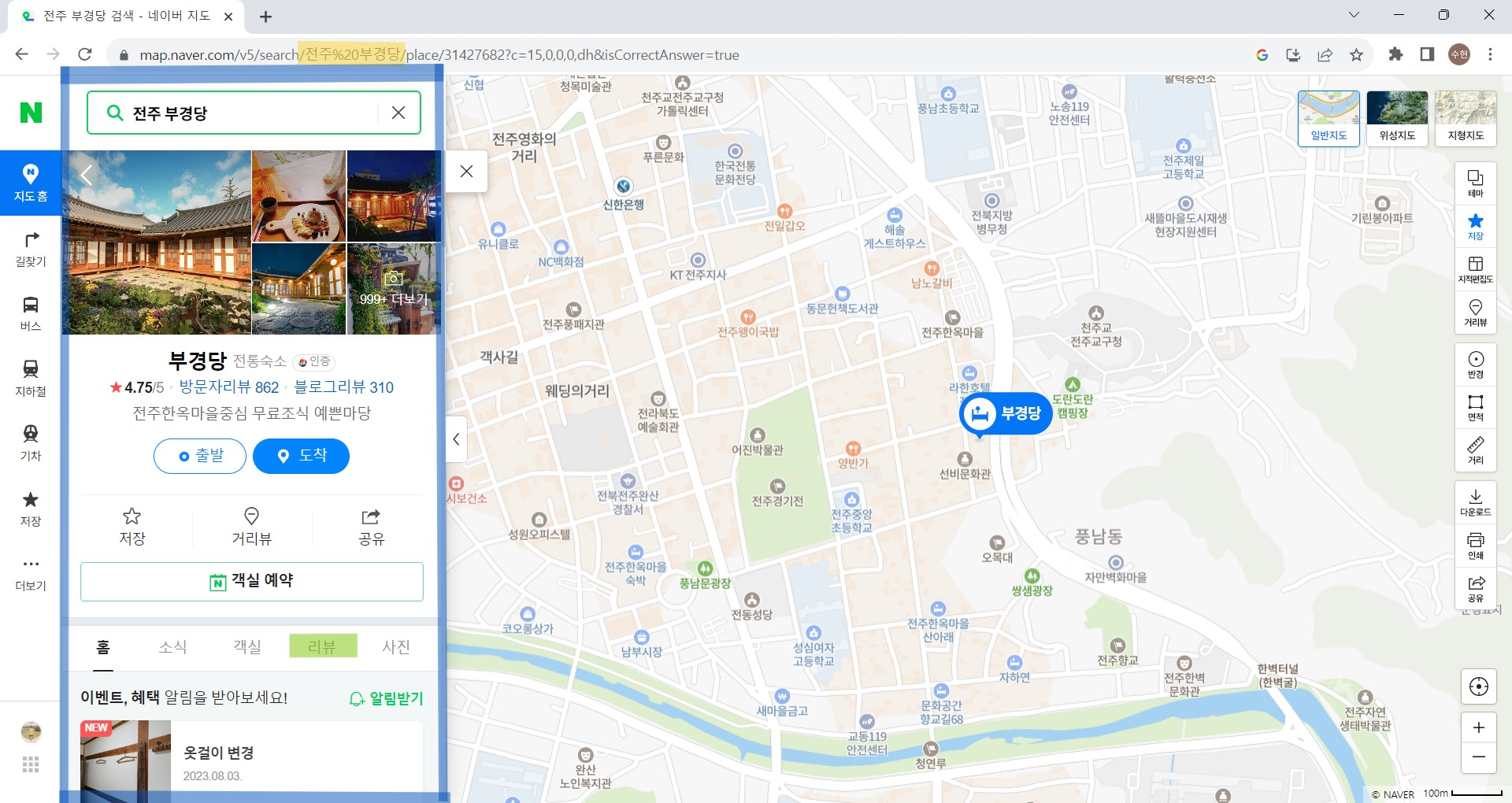
코드의 이해를 위해 사진을 덧붙이자면 url에서 str(i)로 된 부분에 df ['업소명']의 요소가 들어가 다음과 같이 검색되고,
try-except문을 사용하여 검색결과가 존재하면 다음과 같은 사진처럼 해당 숙소에 대한 검색 결과가 나타날 것이므로 iframe으로 이동을 try 하는 것이다.
만약 검색 결과가 존재하지 않으면 iframe이 없으므로 except문을 실행한다.
그다음으로 리뷰 탭을 선택한다.
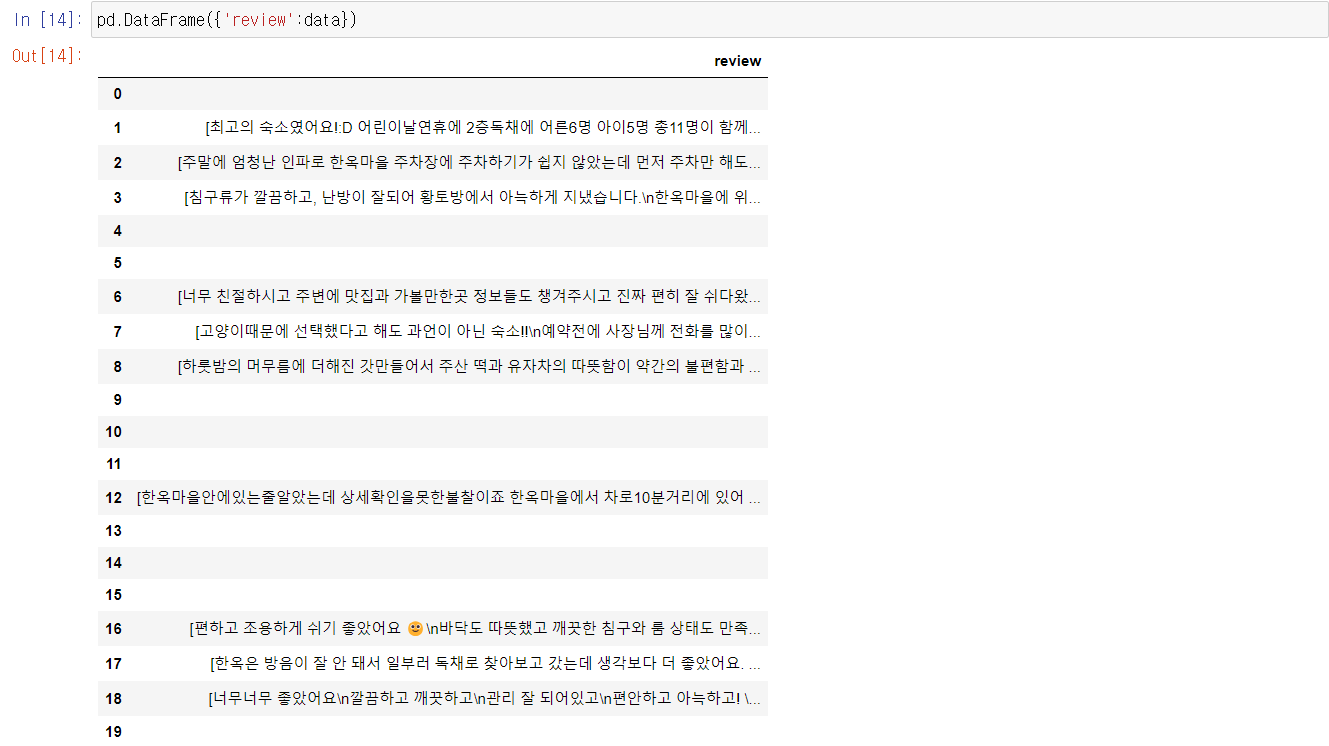
크롤링이 완료된 후 리뷰가 저장된 data를 출력해 보면 다음과 같이 각 숙소별 리뷰가 하나의 리스트 단위 []로 저장된 것을 볼 수 있다.

data를 DataFrame으로 만들어보면 다음과 같다.
리뷰가 없거나, df['업소명']으로 검색했을 때 결과가 나타나지 않으면 except로 인해 해당 row가 비어있는 것을 볼 수 있다.