공모전 준비를 위해 작성했던 크롤링 코드를 정리하는 글입니다.
크롤링 과정을 간단히 작성하면 다음과 같다.
- 크롬 웹드라이버에서 '전주 한옥숙소' 검색
- 검색 결과에서 상세정보 탭으로 이
- 상세정보에서 리뷰 추출
먼저 webdrvier-manager를 설치한다.
pip install webdriver-manager
time 라이브러리와 warning을 무시하기 위한 라이브러리를 import 한다.
import time
import warnings
warnings.filterwarnings('ignore')
크롤링을 위해 필요한 라이브러리도 import 해준다.
동적 크롤링을 위해 selenium을 사용하였고, webdriver로는 크롬드라이버를 사용했다.
from selenium import webdriver # 동적크롤링
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
크롬 웹 드라이버에서 카카오맵으로 이동한다.
# 카카오 맵으로 이동
url = "https://map.kakao.com/"
driver.get(url)
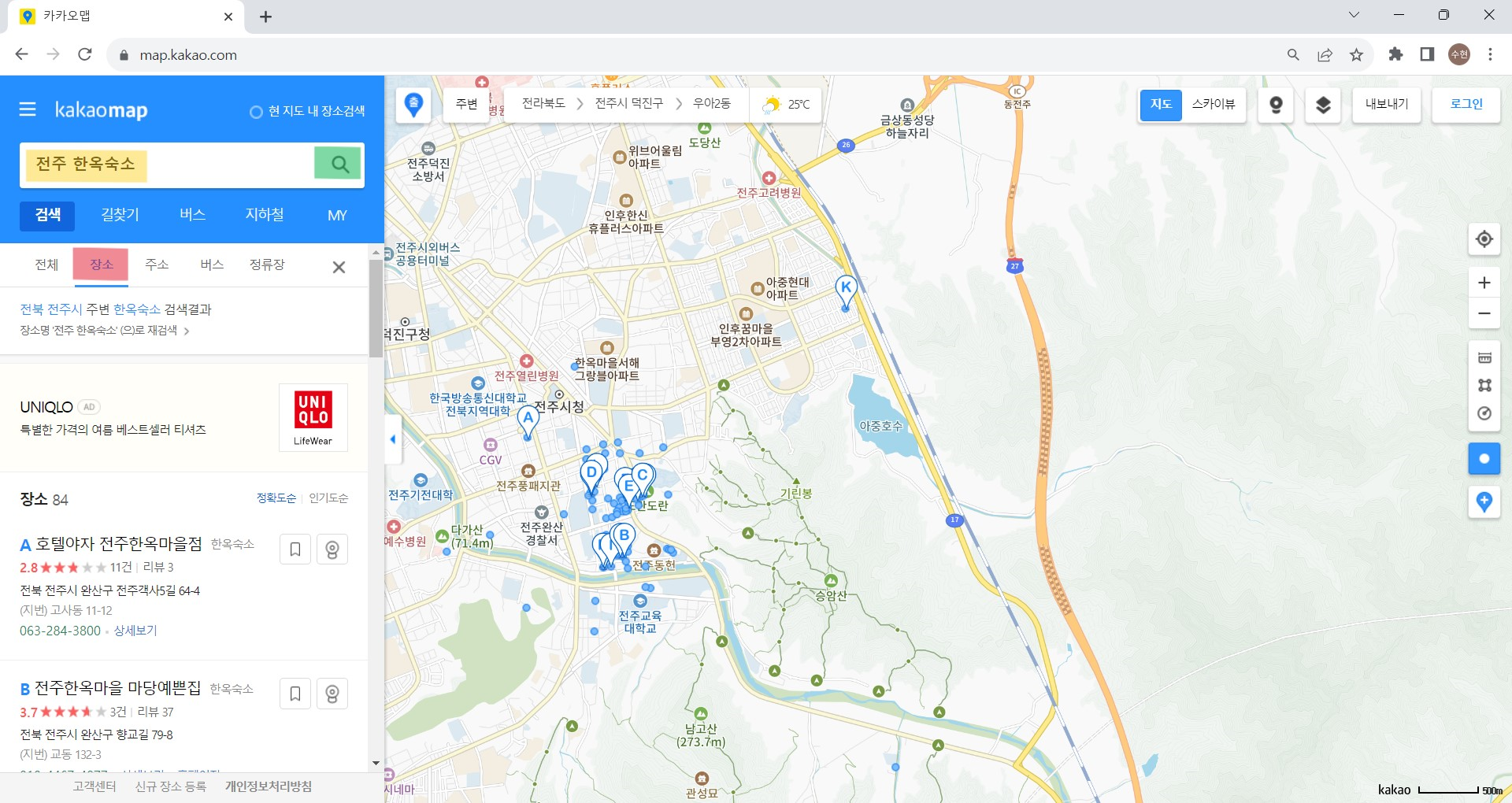
검색어(searchloc)를 '전주 한옥숙소'로 설정하고 카카오맵 검색창에 검색어를 전달해 검색한다.
검색 결과가 나올 때까지 5초 대기 후 장소 탭을 클릭한다.
searchloc = '전주 한옥숙소'
search_area = driver.find_element(By.XPATH, r'//*[@id="search.keyword.query"]') # 카카오맵 검색창
search_area.send_keys(searchloc) # 검색어 전달
driver.find_element(By.XPATH, r'//*[@id="search.keyword.submit"]').send_keys(Keys.ENTER) # 돋보기 클릭
time.sleep(5)
driver.find_element(By.XPATH, r'//*[@id="info.main.options"]/li[2]/a').send_keys(Keys.ENTER) # 장소 탭
과정 이해를 위해 사진을 덧붙이자면 다음과 같다.
카카오맵 검색창 영역에 검색어(searchloc)를 입력하고, 돋보기를 클릭하여 검색 결과를 볼 수 있게 한다.
그다음 장소 탭을 클릭하여 장소 정보만 볼 수 있도록 한다.
숙소 정보를 저장할 빈 리스트 room_list를 만든다.
room_list = [] # 숙소 정보 저장
roomNamePrint 함수를 만든다.
이 함수는 내부에서 리뷰 크롤링 함수인 extract_review를 호출해 최종적으로 이름, 점수, 주소, 리뷰가 room_list에 저장된다.
def roomNamePrint():
time.sleep(0.2)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
room_lists = soup.select('.placelist > .PlaceItem') # 장소 정보를 모두 가져옴
for i, room in enumerate(room_lists):
temp = []
name = room.select('.head_item > .tit_name > .link_name')[0].text
score = room.select('.rating > .score > em')[0].text
addr = room.select('.addr > p')[0].text
# 상세정보 탭으로 이동
driver.find_element(By.XPATH, r'//*[@id="info.search.place.list"]/li['+str(i+1)+']/div[5]/div[4]/a[1]').send_keys(Keys.ENTER)
driver.switch_to.window(driver.window_handles[-1])
time.sleep(2)
rev = extract_review() # 리뷰 추출 함수 실행
# 하나의 리스트로 만들어 room_list에 추가
temp.append(name)
temp.append(score)
temp.append(addr[3:])
temp.append(rev)
room_list.append(temp)
함수 extract_review는 다음과 같다.
li 태그로 작성된 후기 목록을 찾아 후기 존재여부를 파악한 후 존재하면 크롤링을 진행하고, 없으면 빈칸을 추가한다.
def extract_review():
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 후기 목록 찾기
review_lists = soup.select('.list_evaluation > li')
count = 0
rev = []
# 리뷰가 있는 경우
if len(review_lists) != 0:
for review in review_lists:
comment = review.select('.txt_comment > span')[0].text # 리뷰
if len(comment) != 0:
rev.append(comment)
# 없으면 빈칸 추가
else:
rev.append(' ')
# 다시 검색 탭으로 전환
driver.close()
driver.switch_to.window(driver.window_handles[0])
time.sleep(2)
return rev
카카오맵 같은 경우는 한 페이지 내에서 모든 정보가 제공되지 않는다.
상세 보기를 클릭하면 새로운 탭으로 이동되기 때문에 한 숙소에 대한 리뷰 크롤링이 끝나면 이전 탭으로 전환되어야 한다.
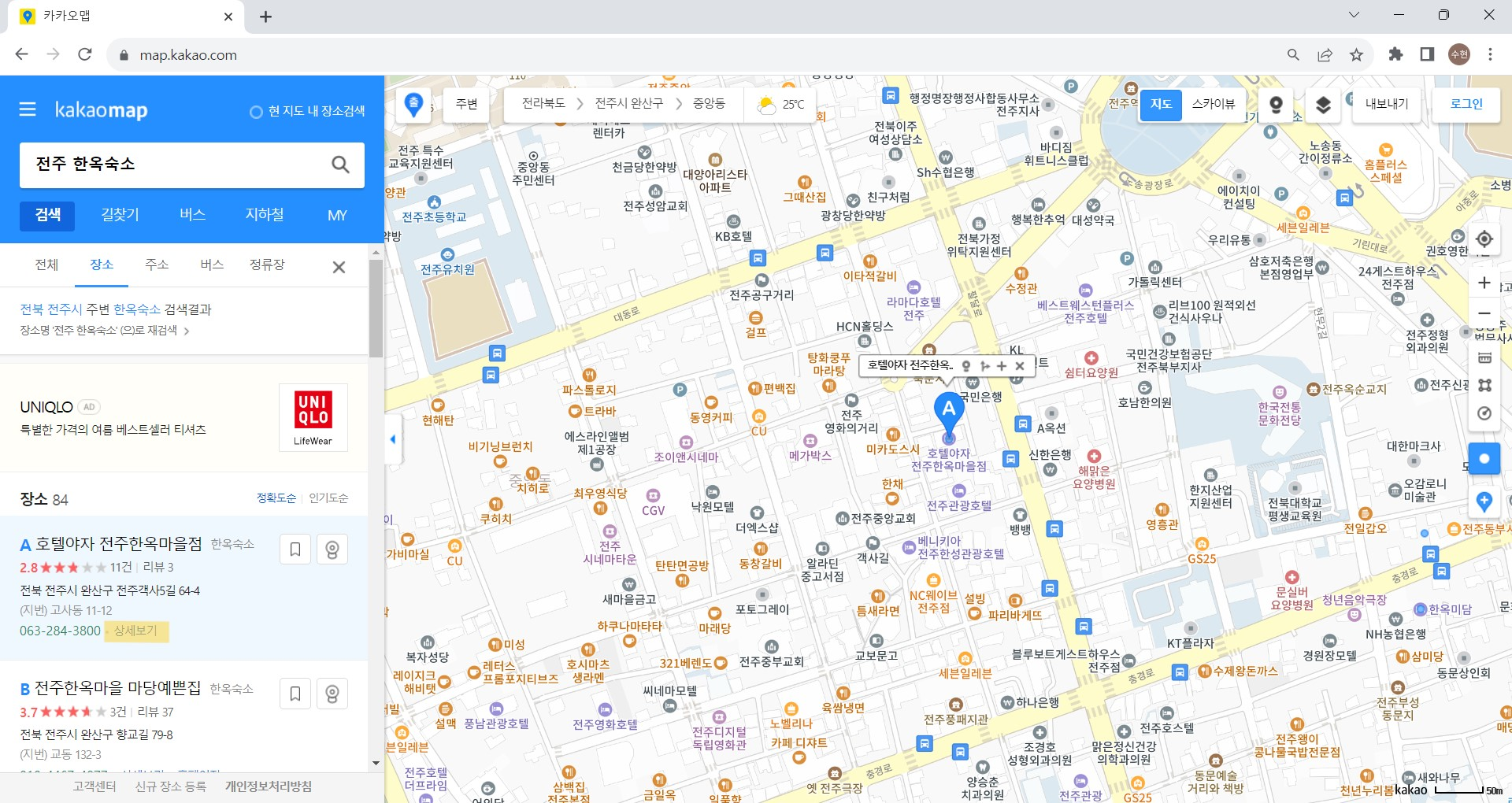
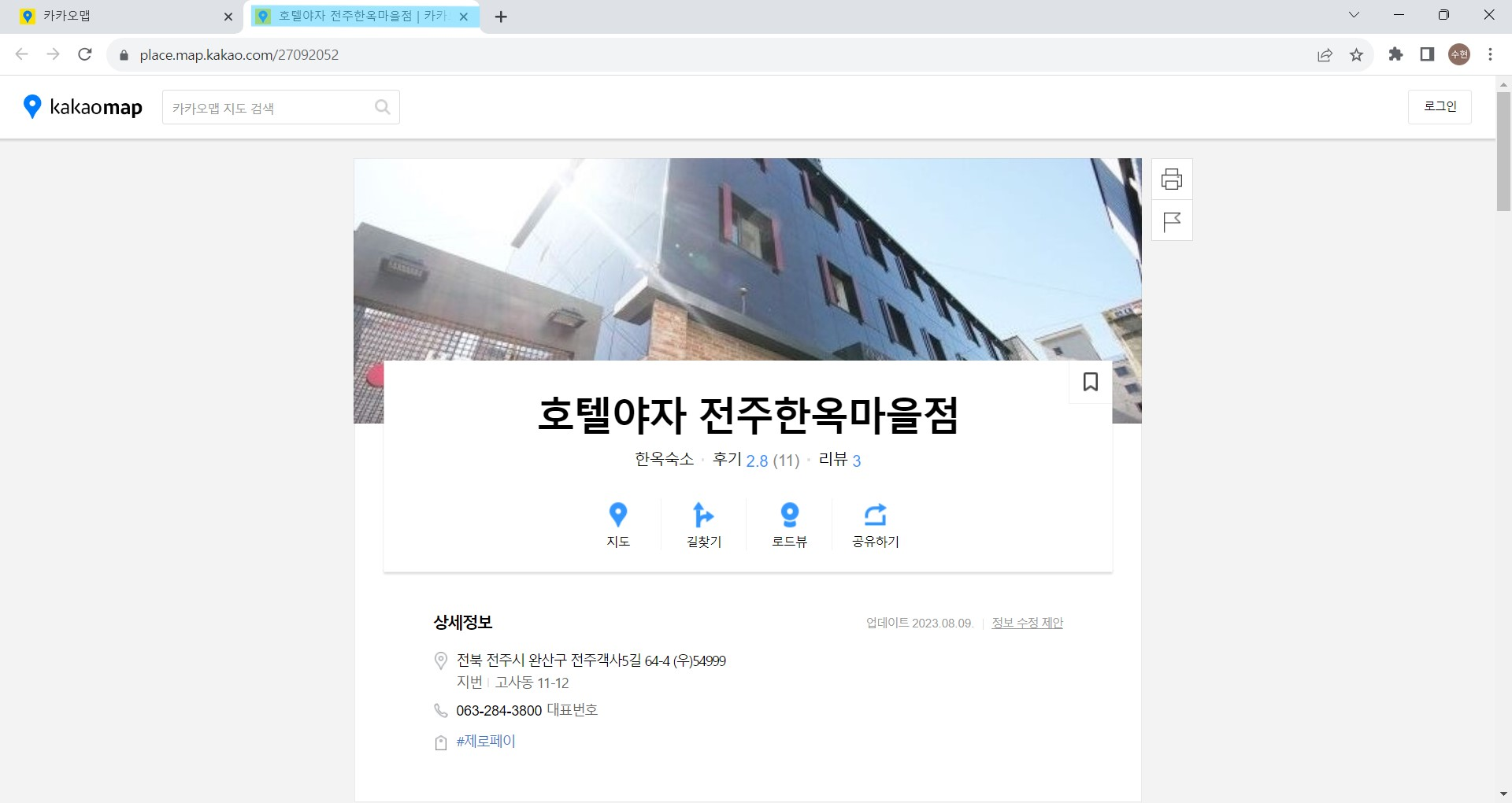
모든 검색 결과에 대한 크롤링을 시작한다.
총 페이지 수가 몇인지 확인한 수 for문의 range에 작성해 주면 된다.
page = 1 # 현재 페이지
page2 = 1 # 5개 중 몇번째인지(버튼이 5개씩있어서 6번째가 되면 다시 1로 바꿔줘야함)
# 전주 한옥숙소: 8페이지
# 북촌 한옥숙소: 2페이지
# 서촌 한옥숙소: 2페이지
# 서울 한옥숙소: 3페이지
# 안동 한옥숙소: 2페이지
for i in range(1, 9):
try:
page2 += 1
print(page, 'page')
# 페이지 버튼 번호(1에서 5 사이 값)
if i > 5:
xpath = '/html/body/div[5]/div[2]/div[1]/div[7]/div[6]/div/a['+str(i-5)+']'
else:
xpath = '/html/body/div[5]/div[2]/div[1]/div[7]/div[6]/div/a['+str(i)+']'
driver.find_element(By.XPATH, xpath).send_keys(Keys.ENTER) # 페이지 선택
roomNamePrint() # 숙소 정보 크롤링
# page2가 5를 넘어가면 다시 1로 바꿔주고 다음 버튼 클릭
if page2 > 5:
page2 = 1
driver.find_element(By.XPATH, r'//* [@id="info.search.page.next"]').send_keys(Keys.ENTER)
page += 1
except:
break
print('크롤링 완료')
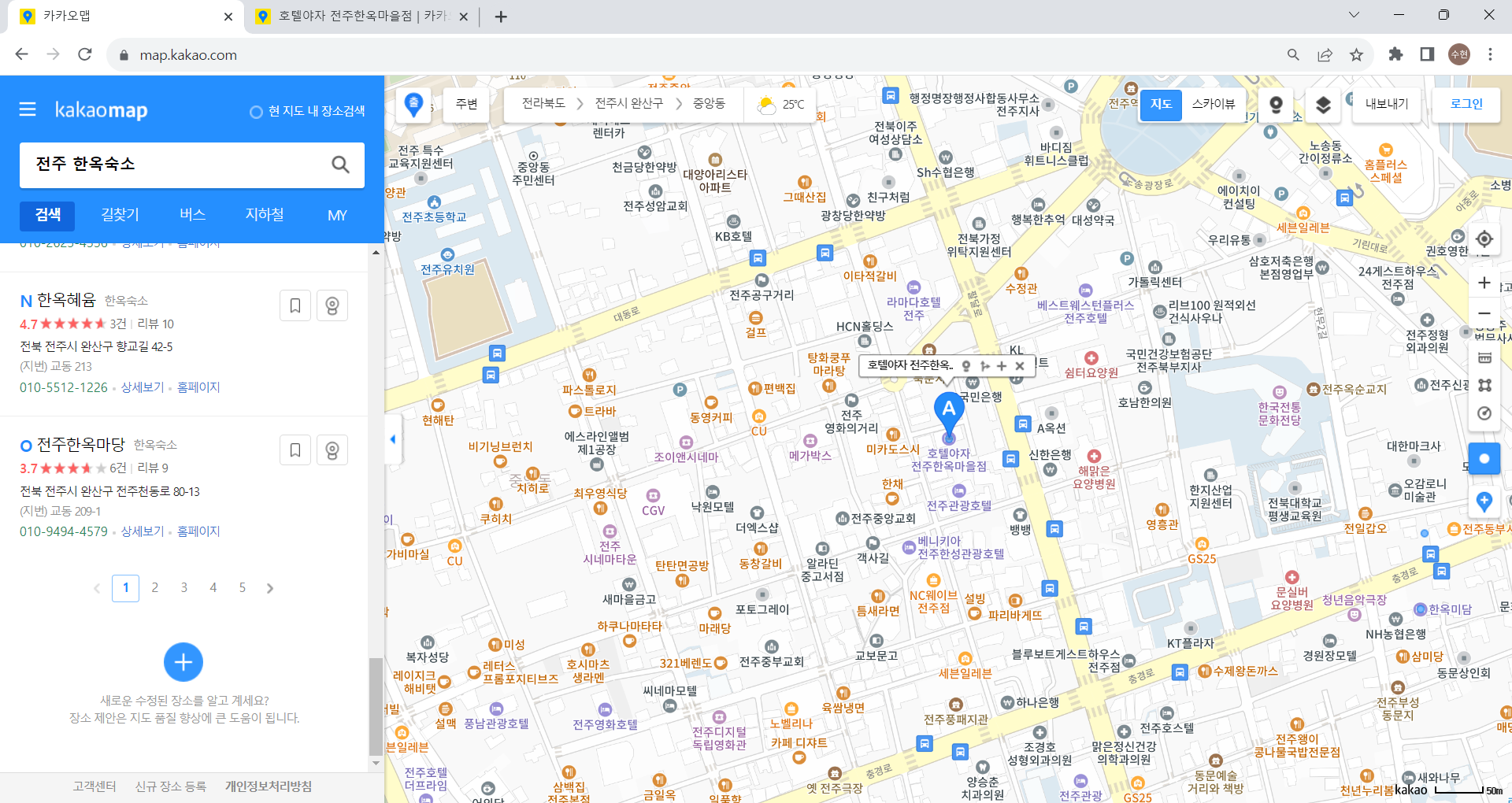
page2 변수 이해를 위해 추가적으로 작성하자면, 아래 사진에서 볼 수 있다시피 카카오맵은 한 번의 검색 결과에서 최대 5개의 페이지를 보여준다.
1,2,3,4,5 다음은 6,7,8,9,10으로 나타나기 때문에 보이는 5개의 페이지 번호 중 몇 번째 페이지인지 저장하기 위해 page2라는 변수를 사용하였다.
page2마다 존재하는 모든 검색결과에 대해 roomNamePrint 함수를 호출해 기본 정보를 저장하고 해당 함수 내에서 extract_review 함수를 호출에 리뷰를 크롤링한다.
크롤링이 완료된 room_list는 다음과 같이 [이름, 점수, 주소, [리뷰들]] 형식으로 저장되어 있는 것을 볼 수 있다.
