10주차 일정
10/10 - 10/11 AI모델 해석/평가
10/12 - 10/13 미니프로젝트 4차

10/10 - 10/11 AI모델 해석/평가
다시 한기영 강사님을 만났습니다!!!!!
그동안 딥러닝으로 지쳐있다가 한기영 강사님 뵙게 되어 마음이 너무 편해졌던 소중한 이틀 동안...♡
XAI(eXplainable AI), 설명 가능한 인공지능을 위해 우리가 만든 모델을 어떻게 해석해야 하는지에 대해서 배웠다.
| 구분 | 모델 전체(Global) | 개별 데이터(Local) |
| 특정 모델 (Model-Specific) | - 트리 기반 모델(DT, RF, XGB등): 변수 중요도(feature importance), tree plot - 선형 회귀, 로지스틱 회귀: 회귀계수 |
|
| 모든 모델 (Model-Agnostic) | - 일반 모델의 변수 중요도: PFI, RFE - X의 변화에 따른 $ \hat y $의 변화: PDP |
- X의 변화에 따른 $\hat y$의 변화: ICE plot - SHAP |
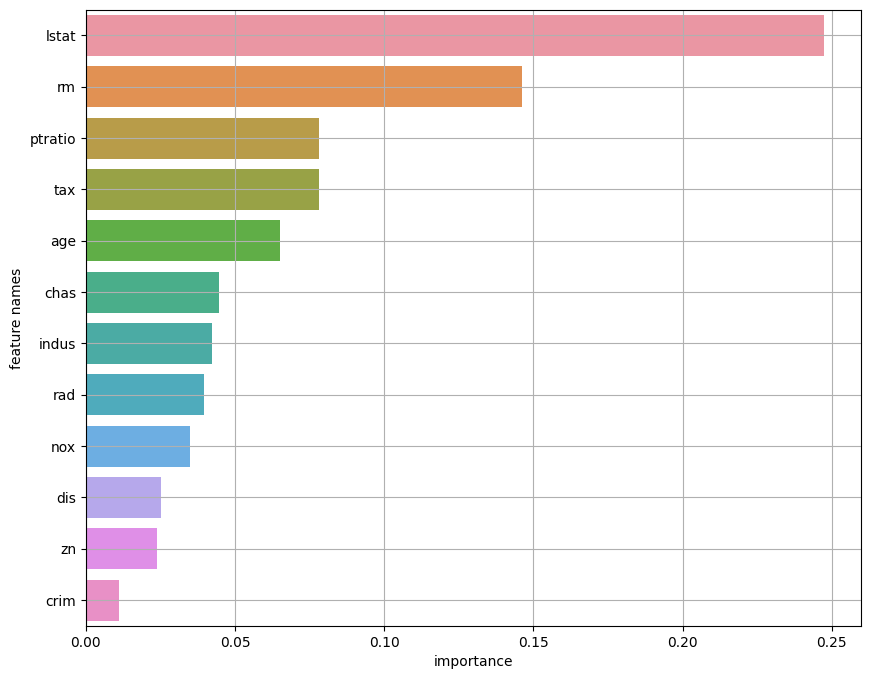
트리 기반 모델 - 변수 중요도 확인
# 기본 모델
model.feature_importances_# 튜닝한 모델
best_model.feature_importances_
부스팅 모델 - 변수 중요도 확인
# 변수 중요도(plot_importance)
plot_importance(model) # importance_type='weight': split 횟수 (기본값)
plt.show()
plot_importance(model, importance_type='gain') # importance_type='gain': 평균 정보이득
plt.show()
plot_importance(model, importance_type='cover') # importance_type='cover': 평균 샘플 수
plt.show()


Permutation Feature Importance(PFI)
알고리즘과 상관없이 변수 중요도를 파악할 수 있는 방법
- Feature 하나의 데이터를 무작위로 섞을 때, model의 score가 얼마나 감소되는 지로 계산
- 만약 다중 공선성이 있는 변수가 존재할 때, 특정 변수 하나가 섞이면 관련된 변수는 그대로 있으므로 Score가 별로 줄어들지 않을 수 있음
from sklearn.inspection import permutation_importance# 모델 훈련(fit) 후
pfi1 = permutation_importance(model1, x_val_s, y_val, n_repeats=10, scoring = 'r2', random_state=2022)- model: 머신러닝, 딥러닝 모델 모두 가능
- x, y
- n_repeats: 반복 횟수
- Output
- importances: feature별 n_repeats만큼 계산된 Score
- importances_mean: 변수별 평균
- importances_sdt: 변수별 표준편차

ICE(Individucal Conditional Expectation) plot
개별 행에서 특정 변수의 변화에 따른 예측 값의 변화(영향력) 시각화
- 변수의 영향력을 파악하는데 유용
- 특정 컬럼의 값들을 모두 추출해 정렬
- 원본 데이터의 해당 컬럼 값을 변경했을 때의 예측값 계산
- 그래프로 그리기
# ICE 함수
def ice_plot(model, x, y, data_1row, var) :
x_values = x[var].sort_values()
pred = []
for v in x_values :
data_1row[var] = v
pred.append(model.predict(data_1row)[0])
sns.lineplot(x = x_values, y = pred)
plt.ylim(y.min(), y.max()) # 실제 값의 범위 지정
plt.grid()
plt.show()
PDP(Partial Dependence Plots)
해당 컬럼에 대한 모든 ICE plot의 평균선 = PDP
- model : 모델
- X : 데이터 셋
- features : 분석할 대상 feature
- kind : 'both' (개별 ICE와 PDP 함께)
from sklearn.inspection import PartialDependenceDisplay, partial_dependence
var = 'lstat'
PartialDependenceDisplay.from_estimator(model, data20, [var], kind="both") # 모델, 데이터, 변수, 종류
plt.grid()
plt.show()
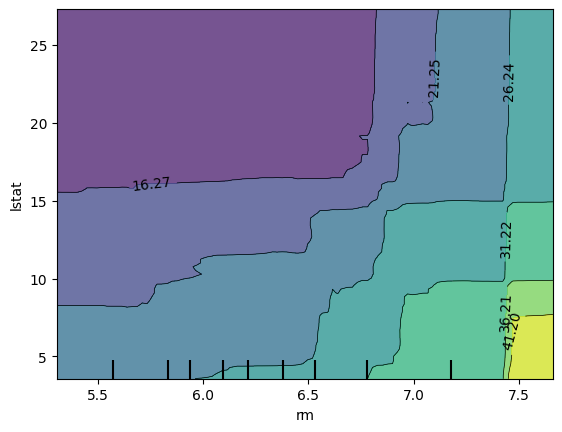
두 변수에 대한 영향력 / 두 변수의 조합과 예측값 비교
# 리스트로 입력 - 두 변수에 대한 각각의 PDP
PartialDependenceDisplay.from_estimator(model, x_train, ['rm','lstat'])
plt.show()# 입력: 리스트 안에 튜플로 입력
PartialDependenceDisplay.from_estimator(model, x_train, [('rm','lstat')])
plt.show()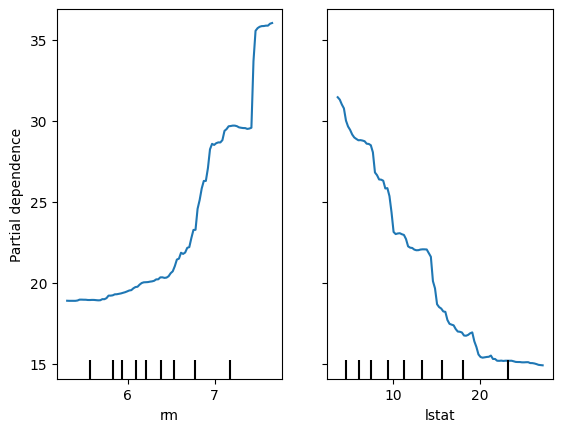
SHAP(SHaply Additive exPlanations)
Shapley value: 모든 가능한 조합에서, 하나의 feature에 대한 평균 기여도를 계산한 값
- Tree 기반 알고리즘(Decision Tree, RandomForest, …) → TreeExplainer
- Deep Learning → DeepExplainer
- SVM → KernelExplainer
- 그 외 일반 알고리즘 → Explainer
1. 모델 생성
model1 = RandomForestRegressor()
model1.fit(x_train, y_train)2. 생성된 모델로 Explainer 만들기
explainer1 = shap.TreeExplainer(model1)
shap_values1 = explainer1.shap_values(x_train)3. 특정 데이터셋에 대한 설명
x_train.iloc[0:1,:] # 0행의 실제 데이터
pd.DataFrame(shap_values1[0:1, :], columns = list(x_train)) # 0행의 shapley value4. 하나의 데이터에서 feature별 기여도 시각화 force_plot(전체평균, shapley_values, input)
shap.initjs() # javascript 시각화 라이브러리(코랩에서는 모든 셀에 포함시키기)
shap.force_plot(explainer1.expected_value, shap_values1[0, :], x_train.iloc[0,:])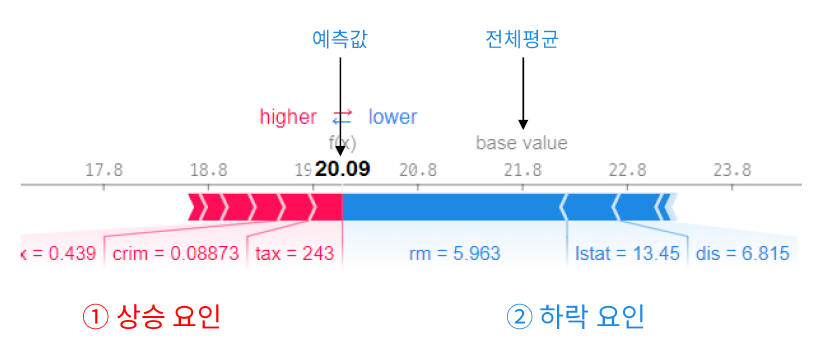
10/12 - 10/13 미니프로젝트 4차
4차 미니프로젝트는 7일간 진행되는데 이틀 동안은 서울시 생활 인구 데이터를 가지고 데이터 전처리부터 모델링까지 해보는 미니프로젝트를 진행했다.
전처리가 끝나면 원본 데이터 기준으로 컬럼이 3개밖에 남지 않아서 당황당스러웠다.(단지 시계열 데이터일 뿐 시계열 예측이 아니었음..!)
나는 rolling과 shift를 이용해서 3시간 동안의 평균 인구수, 7일 전 같은 시간의 인구수 2개의 컬럼을 추가로 만든 뒤 모델링을 진행했는데 예측 그래프를 보면 꽤나 그럴싸했다.

(시간이 지나긴 했지만..^^) 지금 생각해 보면 크게 어려웠던 파트는 없었던 것 같아 주어진 이틀의 시간 동안 충분히 마무리할 수 있었다.
다음 주부터 진행될 진짜 4차 미프가 NLP라는데.. 잘 '못'해낼 거 같다 😥😥
이전 기수 후기로는 캐글 컴피티션도 있었다는데 우리도 할지 그건 쫌 궁금!!