8-9주차 일정
9/25 미니프로젝트 3차
9/26 - 10/6 언어지능 딥러닝
9/26 - 10/6 언어지능 딥러닝
미프는 저번 글에 다 적었으니까 생략하고 언어지능 딥러닝에 대해 이야기를 꺼내보자면...
개인적으로 언어지능 딥러닝은 내 기대치를 충족시키지는 못했다.(블로그 주인장 개인의 의견입니다!!!!!)
'언어지능 딥러닝'을 하면 바로 '자연어 처리'가 생각나는데 자연어 처리에 대한 내용은 많이 배우지 못한 것 같아서...
배운 거라도 잘 정리해야지!!

TF-IDF
- $ TF(t, d) $: 문서 d에서 단어 t의 등장 횟수
- $ IDF(t, D) $: $ DF $의 역수(Inverse)
- $ DF(t,D) $: 전체 문서 D에서 단어 t가 등장한 문서의 수
$$ TF-IDF = TF(t,d) * IDF(t, D) $$
자카드 유사도(Jaccard Similarity)
- 두 문장을 각각 단어의 집합으로 만든 뒤 두 집합을 통해 유사도 측정
- 0과 1 사이의 값을 가짐
import numpy as np
from sklearn.metrics import accuracy_score
# 각 자리의 값이 같은지 확인
print(accuracy_score(np.array([1,3,2]), np.array([1,4,5]))) # 0.3333333333333333
print(accuracy_score(np.array([1,3,2]), np.array([4,1,5]))) # 0.0
print(accuracy_score(np.array([1,1,0,0]), np.array([1,1,0,2]))) # 0.75
print(accuracy_score(np.array([1,0,1,0]), np.array([1,1,0,2]))) # 0.25코사인 유사도(Cosine Similartiy)
- 두 개의 벡터값에서 코사인 각도를 구하는 방법
- -1에서 1 사이의 값을 가짐
from sklearn.feature_extraction.text import TfidfVectorizer
sentence = ('오늘도 폭염이 이어졌는데요, 내일은 반가운 비 소식이 있습니다.',
'오늘도 폭염이 이어졌는데요, 내일은 반가운 비 소식이 있습니다.',
'폭염을 피해 놀러왔다가 갑작스런 비로 망연자실하고 있습니다.')
vector = TfidfVectorizer(max_features=100) # 최대 100개 feature 추출
tfidf_vector = vector.fit_transform(sentence) # sentence를 벡터로 변환
# 코사인 유사도
from sklearn.metrics.pairwise import cosine_similarity
print('[0] and [1]:', cosine_similarity(tfidf_vector[0], tfidf_vector[1]))
print('[0] and [2]:', cosine_similarity(tfidf_vector[0], tfidf_vector[2]))
희소 표현(Sparse Representation)
- 벡터 또는 행렬의 값이 대부분이 0으로 표현되는 방법
- 원-핫 인코딩(one-hot encoding)
- 단어의 개수가 늘어나면 벡터의 차원이 한없이 커짐
- 단어 간 유사성을 표현할 수 없음
- 모든 벡터의 거리가 1로 같음
- 벡터 간의 각도가 90도이기 때문에 코사인 유사도=0
밀집 표현(Dense Representation)
- 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춤
워드 임베딩(Word Embedding)
- 단어를 밀집 벡터의 형태로 표현하는 방법
- 워드 임베딩 과정을 통해 나온 벡터를 임베딩 벡터(embediing vector)라 함
추천 시스템
- 협업 필터링(Collaborative Filtering)
- 고객의 행동 이력을 기반으로 고객의 소비 패턴을 마이닝, 고객-고객, 아이템-아이템, 고객-아이템 간 유사도를 측정, 유사도에 기반하여 아이템을 추천하는 방식
- 사용자의 구매/방문/클릭 이력에 의존한 추천으로 Cosine Similarity 사용
- 피 구매 기록을 바탕으로 모든 아이템 쌍 사이의 유사도를 구하고, 사용자가 구매한 아이템들을 바탕으로 다른 아이템들을 추천
- 모델 기반 협업 필터링(Model-based Collaborative Filtering)
- 기존 아이템 간 유사성을 단순하게 비교하는 것에서 벗어나 데이터 안에 내재한 패턴을 이용하는 기법
- 데이터에 내재되어 있는 패턴/속성을 알아내는 것이 핵심 기술
- 콘텐츠 기반 필터링(Content-based Filtering)
- 아이템의 속성에 기반하여 유사 속성 아이템을 추천하는 방식
- 협업 필터링이 사용자의 행동 이력을 이용하는 반면, 콘텐츠 기반 필터링은 아이템 자체를 분석하여 추천을 구현
- 아이템의 내용을 분석해야 하므로 아이템 분석 및 유사도 측정이 핵심
GAN(Generative Adversarial Network; 적대적 생성 신경망)
서로 다른 두 개의 네트워크를 적대적으로(adversarial) 학습시키며 실제 데이터와 비슷한 데이터를 생성(generative)해내는 모델
- Generator(G, 생성모델, 위조지폐범)
- 목적: 진짜 지폐와 비슷한 가짜 지폐를 만들어 경찰을 속이려 하는 위조지폐범
- 결과: 가짜 지폐 생성
- 실제 지폐를 본 적 없음
- 지도 학습에 속함
- Discriminator(D, 판별모델, 경찰)
- 목적: 위조지폐범이 만들어낸 가짜 지폐를 탐지하려는 경찰
- 결과: 이진분류(가짜로 확신하는 경우 0, 실제로 확신하는 경우 1)
- 진짜 지폐를 알고 있음
- 비지도 학습에 속함
GAN 손실 함수
- 경찰 관점(Discriminator)
- $ D $가 $ max $가 되려면 $ D(x)= 1 $, $ D(G(z))=0 $이 되어야 함
- 진짜 데이터를 진짜로, 가짜 데이터를 가짜로 판별
- 진짜 데이터 $ x $를 $ D $에 입력하면 $ D(x) $가 커지면서 $ logD(x) $가 큰 값이 나오도록
- 가짜 데이터 $ G(z) $를 $ D $에 입력하면 $ D(G(z)) $가 작아지면서 $ log(1-D(G(z))) $가 큰 값이 나오도록
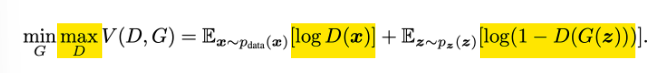
- 위조지폐범 관점(Generator)
- $ G $가 $ min $이 되려면 $ D(G(z))=1 $이 되어야 함
- 진짜로 판별할 만한 가짜 데이터를 만들어야 함
- 가짜 데이터 $ G(z) $를 $ D $에 입력하면 $ D(G(z)) $가 커지면서 진짜 데이터처럼 확률이 높게 나오도록 학습
- $ D(G(z)) $가 커져 $ log(1-D(G(z))) $ 값은 작아지도록 함

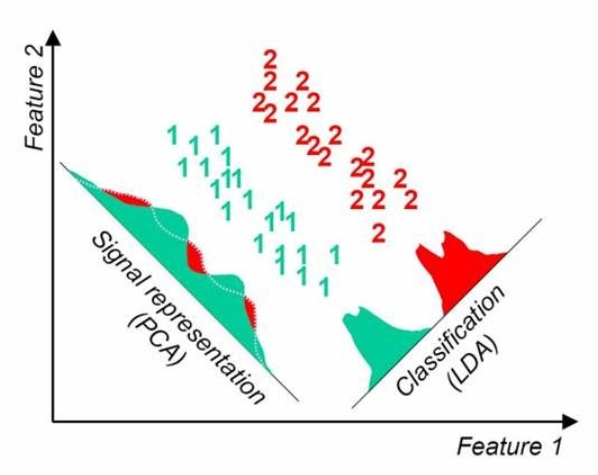
PCA(Principal Components Analysis)
- 데이터를 축에 사영했을 때 가장 높은 분산을 가지는 데이터의 축(주성분)을 찾아 그 축으로 차원을 축소하는 것
- 정보 손실을 최소화(=원래 데이터의 분포를 잘 설명) 하기 위해 높은 분산을 가지는 데이터의 축을 찾음
- 비지도 학습
LCA(Linear Discriminant Analysis)
- 개별 클래스를 분류할 수 있는 기준을 최대한 유지하면서 차원을 축소하는 것
- 클래스 분리를 최대화하기 위해 클래스 간 분산은 크게, 클래스 내 분산은 작게
- 지도 학습
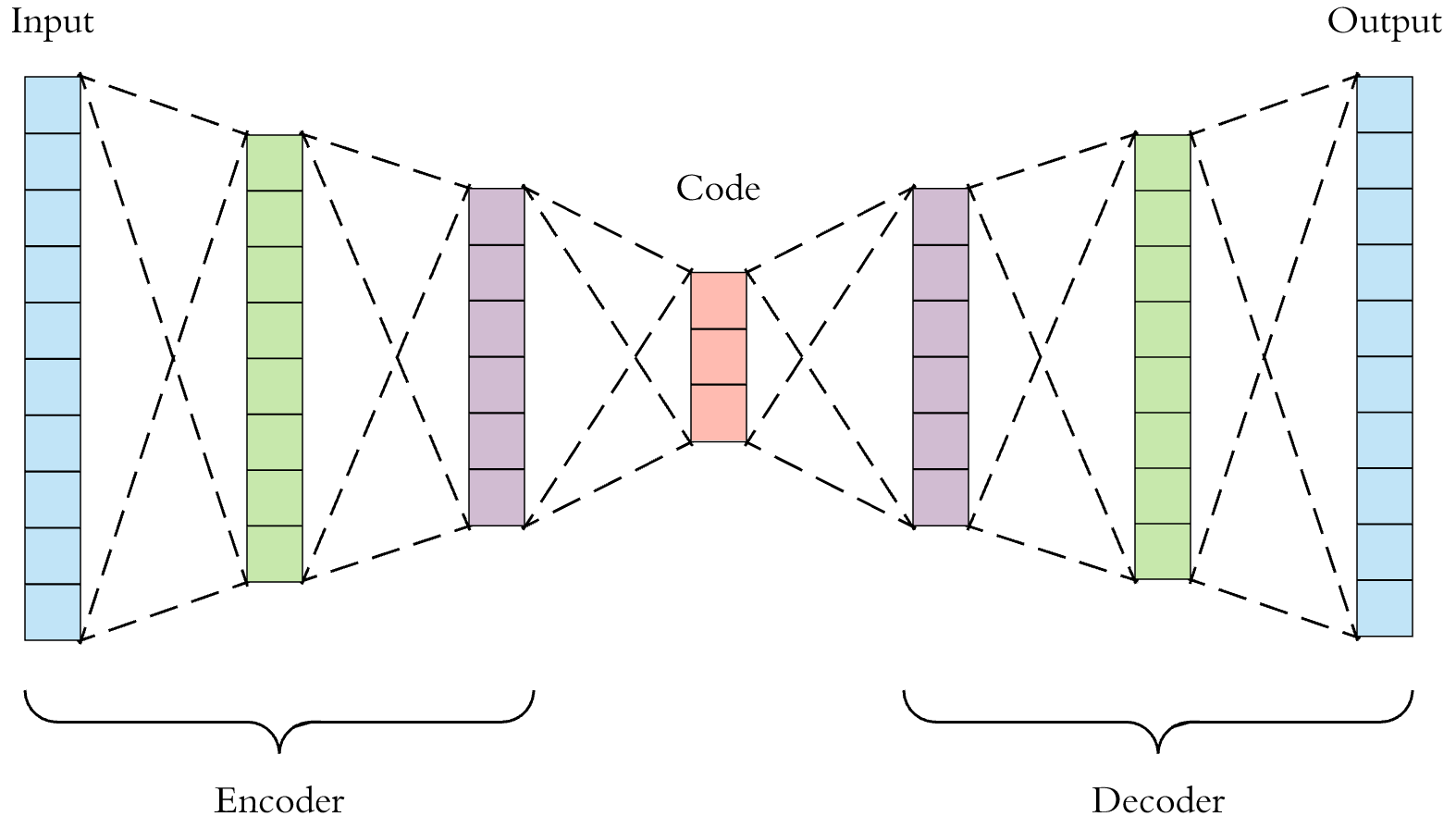
AutoEncoder
입력 데이터를 저차원의 벡터로 압축한 뒤 원래 크기의 데이터로 복원하는 신경망
- 데이터가 입력되면 encoder를 통해 저차원의 벡터로 변환
- 이를 decoder가 받아서 원래 크기의 데이터로 출력
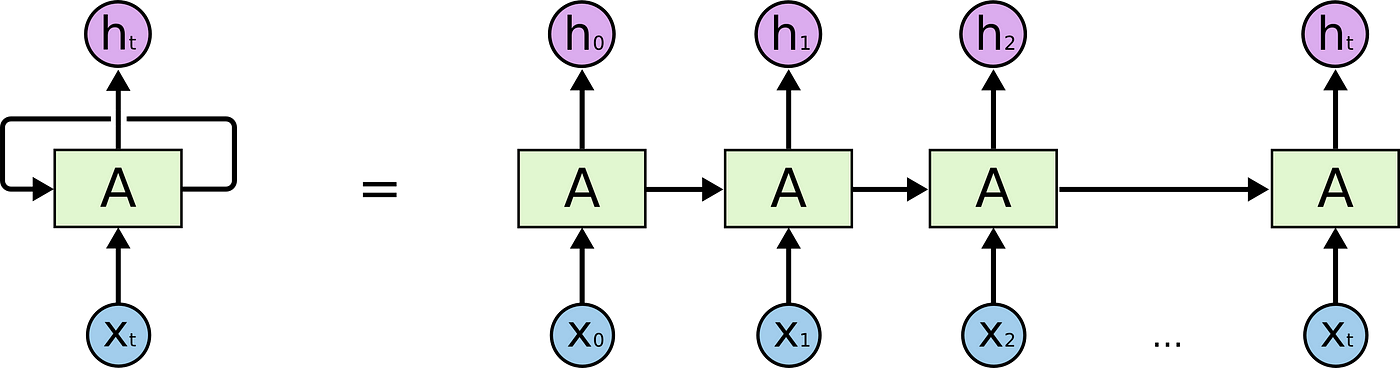
RNN(Recurrent Neural Network)
- A의 결과는 다시 A로 들어가 루프가 만들어짐
- 즉, 이전 상태가 그다음 상태에 영향을 미침
RNN 수식
$$ h_t = f_w(h_{t-1}, x_t) $$
- $h_t$: 다음 상태(new state)
- $f_w$: $w$에 대한 함수
- $h_{t-1}$: 이전 상태(old state)
- $x_t$: $t$시점의 입력값
추석 연휴가 껴있어서 그런 건지 수업을 듣는 내 자세가 엉망이었는지 내용이 어려워서 이해를 못 한 건지 뭐가 문제인지 모르겠지만 이번 언어지능 딥러닝 수업은 배워도 배운 거 같지 않은 뜬구름처럼 느껴졌다.
그래서 더 열심히 복습해 보려고 강의 외 추가적인 내용들도 더 찾아보며 정리해 봤는데 뭐랄까 조금 성장한 느낌?
어떤 개념이 있으면 검색은 하되 내용이 어려워서 바로 X를 누르던 내가 일단 읽어 보려고 시도하는 모습을 스스로 발견했다.
자체 필터링이 되어 스펀지마냥 모든 내용을 흡수하진 못하지만 ㅠㅠ 그래도 확실히 발전했다 (뿌듯)
벌써 에이블스쿨이 두 달이나 지났는데 들인 시간만큼 나도 우상향 하는 모습을 계속해서 유지하고 싶다🫠
