9/4 - 9/8 딥러닝
딥러닝 수업 후반부에는 나중에 프로젝트할 때나 앞으로 엄!청! 유용하게 쓰일 것 같은 hugging face와 open ai API를 사용하는 법을 배워서 따로 정리해 보고자 나눠서 쓰는 5주차 후기임다.
Hugging Face 사용하기
Hugging Face에는 이미 학습이 완료된 다양한 모델들이 올라와있어, 사용하고자 하는 목적에 맞는 모델을 선택해 쉽게 사용할 수 있다.
- 데이터셋 로딩
- 모델 로딩
- 모델 사용
Models - Hugging Face
huggingface.co
라이브러리 설치
!pip install transformers
!pip install datasets
!pip install xformers
감정 분석
from transformers import pipeline
classifier = pipeline('sentiment-analysis') # 감정분석 기본 모델
result = classifier('We are very happy')
print(result)
# [{'label': 'POSITIVE', 'score': 0.9998835325241089}]
results = classifier(["We are very happy", "We hope you don't hate it."])
print(results)
# [{'label': 'POSITIVE', 'score': 0.9998835325241089}, {'label': 'NEGATIVE', 'score': 0.5308590531349182}]# 한국어 감정 분석
from transformers import pipeline
classifier = pipeline('sentiment-analysis', 'matthewburke/korean_sentiment') # 한글 감정분석 모델 추가
classifier(['좋아', '별로야'])
# [{'label': 'LABEL_1', 'score': 0.9337605834007263}, {'label': 'LABEL_0', 'score': 0.9618430137634277}]
텍스트 생성
from transformers import pipeline
generator = pipeline('text-generation') # 텍스트 생성 모델
results = generator('I have a dream')
print(results[0]['generated_text'])# 한국어 텍스트 생성
from transformers import pipeline
generator = pipeline('text-generation', 'skt/kogpt2-base-v2') # 한국어 텍스트 생성 모델 추가
results = generator('나의 미래는?', max_length=100)
print(results[0]['generated_text'])
Gradio를 이용해 앱 만들기
Gradio는 딥러닝 엔지니어가 앱을 쉽게 만들 수 있도록 도와주는 프레임워크이다.
Gradio Interface Docs
Interface is Gradio's main high-level class, and allows you to create a web-based GUI / demo around a machine learning model (or any Python function) in a few lines of code. You must specify three parameters: (1) the function to create a GUI for (2) the de
www.gradio.app
라이브러리 설치
!pip install gradio
기본 코드
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch(share=True, debug=True)
한국어 텍스트 생성 앱(hugging face + gradio)
# 한국어 텍스트 생성 앱
import gradio as gr
def greet(word):
generator = pipeline('text-generation', 'skt/kogpt2-base-v2') # 모델
result = generator(word, max_length=100)
return result[0]['generated_text'] # 생성된 텍스트 리턴
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch(share=True, debug=True)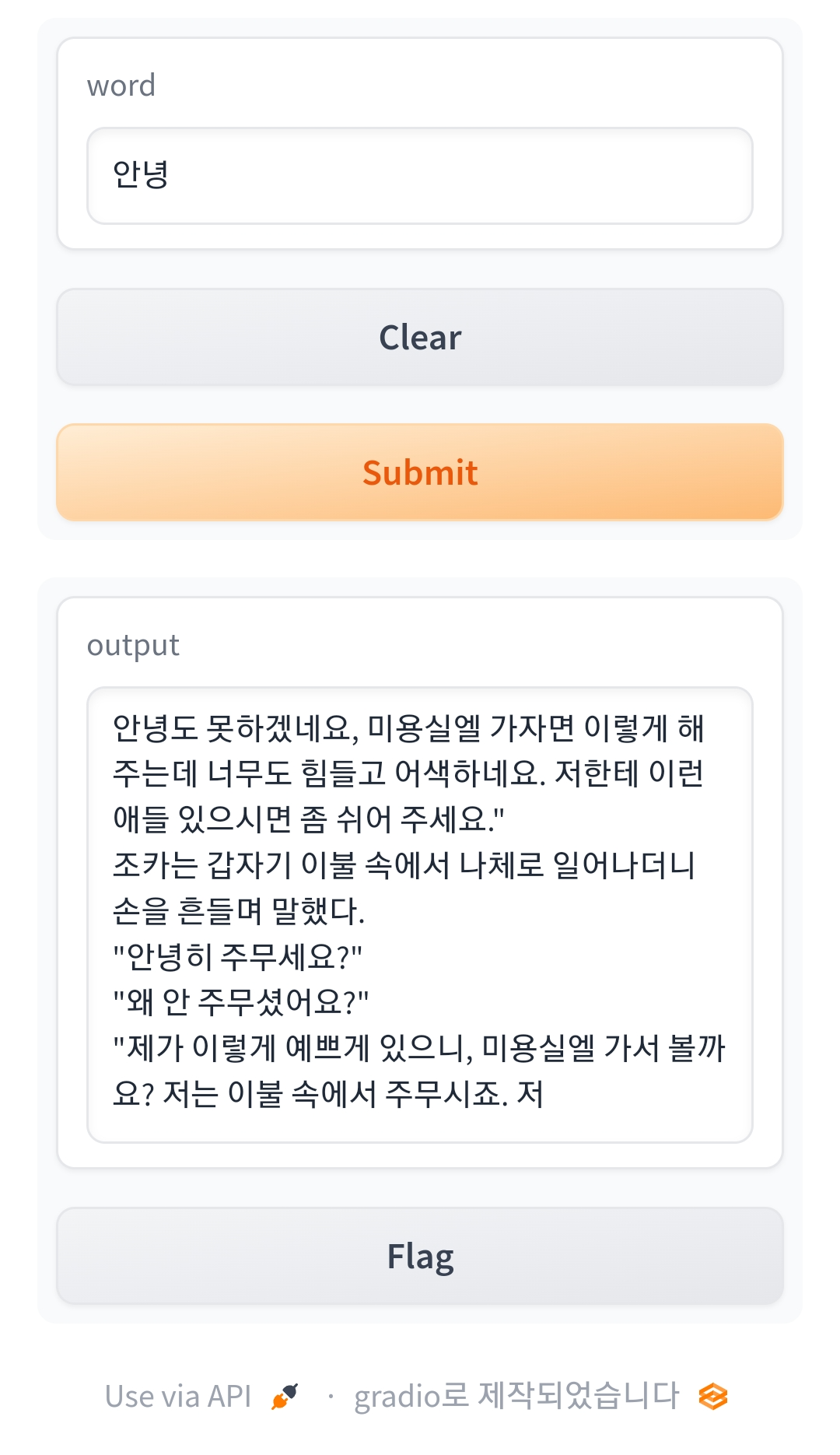
Open AI
세상을 바꿔놓은 Chat gpt를 직접 API를 이용해 내 맘대로 사용할 수 있다.
OpenAI Platform
Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI's platform.
platform.openai.com
라이브러리 설치
!pip install openai
Chat gpt API 사용
parameters
- temperature: 값이 클수록 다양한 문장 생성
- max_tokens: 생성 텍스트의 최대 길이
- top_p
- frequency_penalty
- presence_penalty
# chat gpt
import os
import openai
openai.api_key = '##########################'
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "넌 나의 선생님이야."},
{"role": "user", "content": "오늘 점심메뉴는 무엇인가요?"}
],
temperature=0.7,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
print(response.choices[0].message['content'])
# 점심 메뉴는 제가 결정할 수 없어요.
# 하지만 여러 가지 옵션을 제안해 드릴 수는 있어요. 어떤 음식이 좋아하시나요?
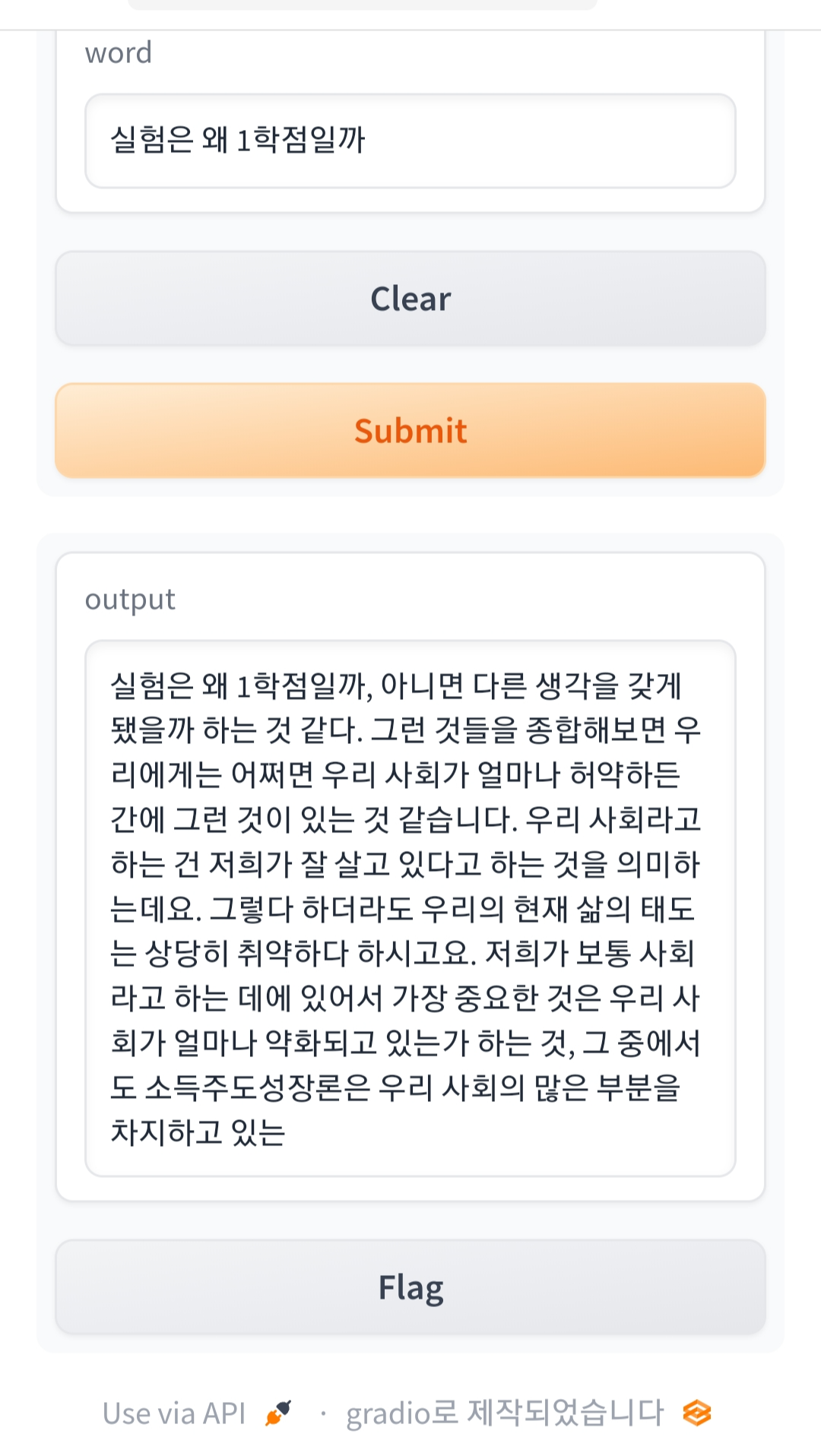
텍스트 생성 앱(Gradio + openai)
import gradio as gr
import openai
openai.api_key = '##########################'
def 텍스트생성(prompt):
response = openai.Completion.create(
model="text-davinci-003",
prompt=f"{prompt} \n의 앞으로의 10년 미래를 예측해줘", # 프롬포트 엔지니어링
temperature=0.7,
max_tokens=1024,
)
return response.choices[0].text.strip()
demo = gr.Interface(fn=텍스트생성, inputs='text', outputs='text')
demo.launch(share=True)
토큰과 임베딩
토큰(token): 뜻을 지니는 가장 작은 단위의 단어 조각
토큰화(tokenize): 주어진 텍스트를 토큰(token)이라 불리는 단위로 나누는 작업
임베딩(Enbedding): 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 혹은 그 과정 전체
- 토큰들 사이의 관계를 표현하기 위한 방법
- 토큰 공간 속의 좌표로 옮기는 과정
- 비슷한 특징을 가지는 토큰은 비슷한 위치에 존재하고
- 비슷한 관계를 가지는 단어들은 단어들 간의 거리를 비슷하게 매핑
일주일간 딥러닝을 배우면서 기초 개념들을 이해하느라 너무 허덕여서 개인적으로는 제일 재밌었던 시간이었다.
특히, gradio를 사용해 이런저런 앱들을 만들면서 친구들한테 실시간으로 "얘들아 이거 해봐"하고 링크를 보내줬는데 다들 재밌게 사용하는 모습들을 보여줘서 이런 기분에 공부하고 개발하는 건가 싶었다 ㅎ_ㅎ
수업 시간에 했던 예제들 외에도 "oo이의 앞으로 10년 미래를 예측해 줘"와 같이 프롬포트를 직접 변경해 보니 프롬포트 엔지니어의 역할도 크게 느낄 수 있었다.
이전에 참가했던 공모전이 생각나면서 그때 이런 것들을 알았다면 더 좋은 결과물을 만들 수 있지 않았을까 하는 아쉬움도 남고 앞으로 하게 될 프로젝트나 공모전에 잘 녹여보고 싶다.
딥러닝 수업이 끝나자마자 바로 미니프로젝트가 진행되는데 딥러닝 코드를 작성해 본 경험이 적다 보니 잘 해낼 수 있을지 걱정이 많지만 잘해보자!!
