프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
처음 시도한 코드
def solution(s):
answer = ''
s = s.split(' ')
for word in s:
for i in range(len(word)):
if i % 2 == 0:
answer += word[i].upper()
else:
answer += word[i].lower()
answer += ' '
return answer.rstrip()주어진 문자열의 각 단어별 짝수번째 인덱스는 대문자로, 홀수번째 인덱스는 소문자로 나타내는 문제이다.
각 문자의 인덱스가 짝수인지 홀수인지 판별하여 각각 upper(), lower()를 사용하면 쉽게 해결할 수 있다.
하지만 위 코드를 정답으로 제출했을 때 절반 이상의 케이스에서 실패했다.
그 이유는 다음과 같다.
s에서 word를 하나씩 가져와 대소문자 변경과정을 진행하고, 하나의 word가 끝나면 공백을 추가해 준다.
공백으로 s를 분리했기 때문에 다시 문자열로 나타내기 위해 공백을 추가하는 것이다.
하지만 return에서 문제가 발생한다.
당연히 마지막 word가 끝나고 추가한 공백은 지워줘야 한다고 생각해, 오른쪽에 위치한 공백을 제거하는 rstrip()을 사용했다.
rstrip()은 오른쪽에 위치한 "모든" 공백을 제거한다. 그렇기 때문에 마지막 word의 마지막 인덱스에 공백이 있었으면 word에 포함된 공백도 지운다는 것이다.
말로 설명하기에는 어려울 것 같아 직접 예를 하나 실행시켜 보았다.
soution에 'hello ddu '를 매개변수로 전달했을 때, answer[:-1]의 결과와 answer.rstrip()의 결과를 각각 출력해 보면 HeLlO DdU로 똑같이 나온다.
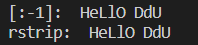
하지만 answer[:-1] == answer.rstrip()을 해보면 False이다. 둘이 같지 않다는 것이다.
실제로 어떻게 다른지 answer[:-1]과 answer.rstrip()을 리스트로 바꿔 각 요소들을 살펴보았다.


answer[:-1]에는 DdU 다음에 공백이 하나 존재하는 것을 볼 수 있다.
반면, answer.rstrip()에는 DdU다음에 공백이 없다.
주어진 문자열은 'ddu '이기 때문에 ddu 다음에 공백이 하나 있어야 한다.
하지만 rstrip() 특성상 전체 문자열의 오른쪽에 위치한 공백을 모두 제거해 버리기 때문에 이와 같은 결과가 출력되는 것이다.
정답 코드
def solution(s):
answer = ''
s = s.split(' ')
for word in s:
for i in range(len(word)):
if i % 2 == 0:
answer += word[i].upper()
else:
answer += word[i].lower()
answer += ' '
return answer[:-1]따라서 위 코드에서 return문을 answer.rstrip()이 아닌 answer[:-1]로 해주어야 구하고자 하는 답을 찾을 수 있다.
다른 방법
def solution(s):
answer = []
s = s.split(' ')
for word in s:
temp = ''
for i in range(len(word)):
if i % 2 == 0:
temp += word[i].upper()
else:
temp += word[i].lower()
answer.append(temp)
return ' '.join(answer)
공백을 생각해야 한다는 점에서 위 코드가 조금 귀찮게 느껴질 수도 있다. 그래서 다른 방식으로도 풀어보았다.
answer를 문자열이 아닌 리스트로 선언한다.
그다음, 똑같이 문자열 s에서 word를 대소문자로 바꾼다. 이때 다른 점은 temp에 각 문자별 대소문자 변경 결과를 저장한다.
하나의 word가 끝나면 변경 결과인 temp를 word에 추가하고, 모든 과정이 종료되면 answer에 있는 요소들을 공백(' ')으로 연결하여 결과를 도출한다.
이렇게 하면 매 단어가 끝날 때마다 공백을 추가하지 않아도 되고, word에 공백이 추가되어 있을 경우 return에서 어떻게 반환해야 할지 고민하지 않아도 된다.