더 많은 데이터를 경험하고 코드 작성에 대한 스킬을 습득하기 위해 캐글 필사를 시작하였다.
[이유한님] 캐글 코리아 캐글 스터디 커널 커리큘럼을 따라서 진행할 계획이며, 첫번째 데이터에 대한 필사는 마친 상태이다.
필사는 캐글 안에서 진행하며 노트북은 모두 깃허브에 업로드 하고 있으며, 새로 알게된 함수나 헷갈렸던 부분에 대해서는 Issue에 하나씩 추가하고 있다.
하나의 데이터에 대한 여러 노트북들을 모두 완료하면 하면서 느낀 점과 새로 알게된 부분들을 블로그에 기록하려고 한다.
첫번째 데이터인 타이타닉에 대한 세가지 노트북을 3주간에 걸쳐 모두 필사하였다.
1. EDA To Prediction(DieTanic)
노트북 이름에서 볼 수 있듯이 예측을 위해 EDA(탐색적 데이터 분석)을 위주로 진행하였다.
seaborn에 있는 내장 함수들을 이용하여 그래프를 그렸는데, 보통 필요한 그래프에 대한 코드는 그때그때 찾아서 문제를 해결하다보니 적혀있는 코드를 보고 따라 적으면서도 새롭게 알게되는 부분들이 많았다.
pandas의 crosstab은 이번 필사를 하며 처음보았다.
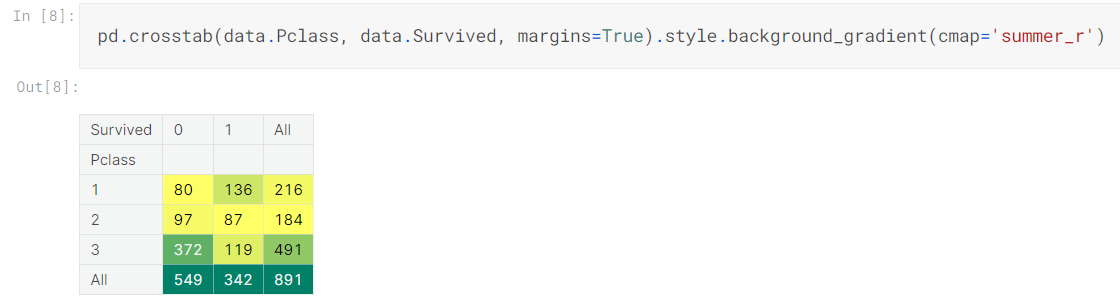
groupby를 사용해서 나타내기는 하였지만 crosstab을 사용하면 배경색이 존재하기 때문에 어떤 값이 가장 많은 빈도수를 보이는지 쉽게 확인할 수 있었다.
또한, subplots을 그리는 것도 익숙치 않아 종종 찾아보며 시각화하곤 했는데, 이번 기회에 많은 subplots들을 그려보며 조금이나마 손에 코드가 익숙해진 것 같다.

가끔가다 subplots이 안그려지고 각각 그려지는 경우도 있었다. 아직까지 원인은 잘 모르겠다.. 코드는 분명히 올바르게 작성했는데 왜 그래프가 각각 그려지는지 계속해서 다른 노트북들을 필사하다보면 알 수 있을 것이라고 생각한다.
이 노트북의 경우는 5년 전에 작성되었기 때문에 파이썬과 라이브러리들의 버전이 바뀌면서 현재 버전에 맞는 코드들을 찾는데 시간이 꽤나 오래 걸렸다.
특히 노트북에 나와있는 factorplot은 현재는 catplot으로 변경되었으며, kind 설정을 통해 원하는 형식으로 그릴 수 있다.
categorical 변수들을 사용하여 그릴 수 있는 plot들이 catplot에 모두 있다고 생각하면 된다.
모델링을 하기 위해서는 어떤 데이터를 가지고 분류/예측할 것인지 결정하는게 가장 어렵게 생각되는 부분 중 하나인데, 이 노트북을 필사하면서 다양한 방식으로 변수를 결정하는 과정을 배웠다.
2. Titanic Top 4% with ensemble modeling
두번째 노트북도 모델링만 제외하면 비슷한 플로우로 데이터 전처리 과정이 진행된다.
보통 어떤 데이터를 사용하고 버릴 지 결정할 때 모델링에 집중하다보면 상관관계 분석만으로 결정하는 경우가 많다.
나 역시도 heatmap만 보며 선택했던 경우가 100중에 100은 되는 것 같다.
하지만 이 노트북에서는 상관관계가 없다고 해서 그냥 넘어가지 않고 하나하나 확인하는 과정을 거쳤다.
시각화를 통해 각 feature와 Survived간의 관계를 파악하여 그래프를 통해 어떤 경우에 생존 확률이 높은지 알아내 새로운 변수를 만들었다.
모델링에서 새로운 모델들을 많이 접하게 되었다.

DecisionTree, RandomForest, LogisticRegression, AdaBoost는 경험이 있지만 나머지 모델들은 들어보기만 했거나 처음 보는 모델들이어서 모델 자체를 이해하는 것 보다는 코드에 집중하였다.
상위 4개의 모델만 가지고 GridSearchCV를 진행하여 최적 하이퍼 파라미터를 구하는 과정이 있었는데, 이 과정에서 어떤 모델에 어떤 하이퍼 파라미터가 있는지 많이 배우게 되었다.

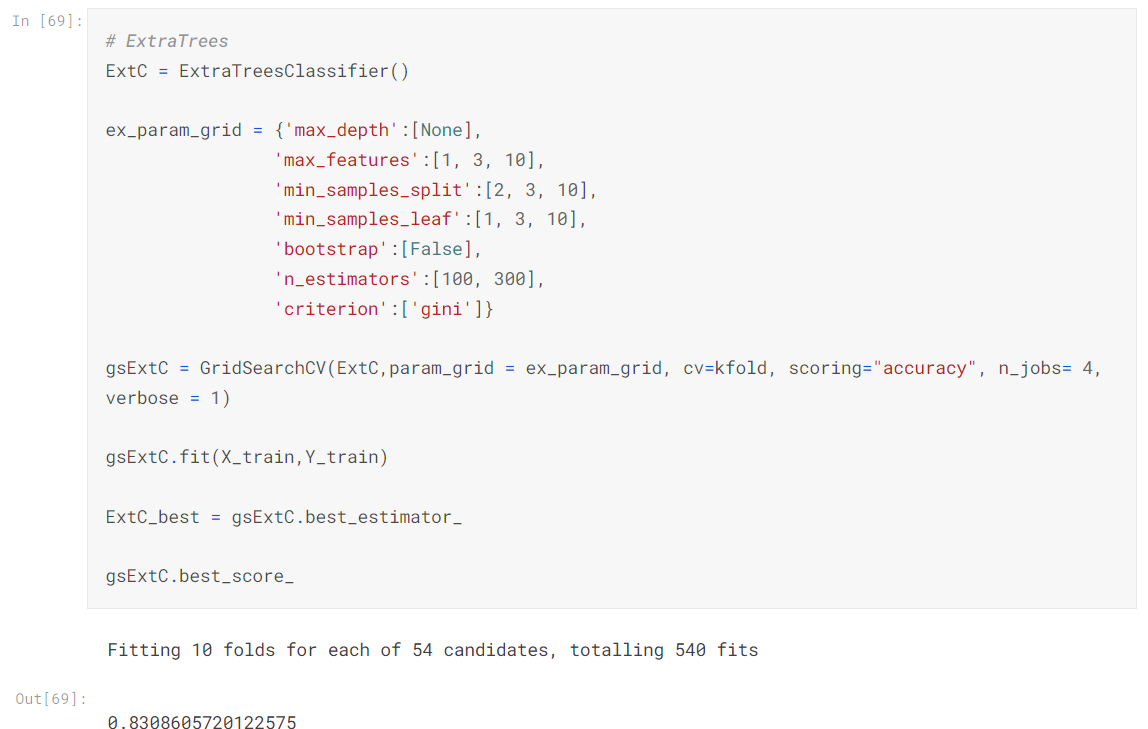
보통 하이퍼 파라미터 튜닝할 때 어떤 파라미터가 있는지 몰라서 검색해서 다른 사람의 코드에 있는 부분만 복붙하거나 했는데 하나씩 보면서 익혀나가야 할 것 같다.
실제로 이때 GridSearchCV에 코드에 적응이 많이 되어서 소모임에서 진행했던 프로젝트에도 이 과정을 녹여낼 수 있었다.
3. Introduction to Ensembling/Stacking in Python
이 노트북은 전처리보다 모델링에 더 집중되어 있다.

전처리는 위 사진과 같이 Cabin같은 명목변수를 0과 1로 바꾸고, 가족 수를 의미하는 새로운 변수를 만들거나, 결측치를 대체하는 것이 전부이다.
Random Forest classifier, Extra Trees classifier, AdaBoost classifier, Gradient Boosting classifier, Support Vector Machine 5개의 분류 모델을 사용하였다.
모델의 수가 5개나 되다보니 split, fit, predict 등의 과정을 매번 반복해야하는데, 그런 불편함을 해소하고자 함수를 만들어 사용하였다.


모든 분류 예측이 끝나면 plotly 패키지를 사용하 feature importace를 시각화하였다.
모델별로 중요한 변수가 다르기 때문에 최종적으로 평균적인 중요도를 구했다.

실제 노트북에서는 그래프 위에 마우스를 올리면 해당 feature의 평균 중요도를 볼 수 있다.
단순히 한 번의 필사만으로는 이 노트북의 내용을 완전히 이해하기는 어렵다.
하지만 전체적인 흐름을 파악하고, 커널 하나하나씩 익히면서 새롭게 알게되는 부분이 정말 많았기에 필사를 계속할 예정이다.
실력을 더 갈고 닦아서 캐글 안에서 열리는 Competitions에도 코드를 제출해보고 싶다.
GitHub - dduniverse/kaggle-copy
Contribute to dduniverse/kaggle-copy development by creating an account on GitHub.
github.com