Porto Seguro’s Safe Driver Prediction 데이터에 관련된 커리큘럼에는 총 4가지의 노트북이 존재한다.
그중 한 가지를 마무리한 지 거의 한 달이 가까이 되었다.
중간에 코테에 한 번 도전해 보려고 준비하느라 그리고 지금 진행 중인 소모임 프로젝트에 시간을 많이 투자해야 할 것 같아 캐글 필사의 우선순위가 뒤로 조금 밀렸다.
다른 노트북까지 필사를 완료하기까지 시간이 조금 걸릴 것 같아 완료한 한 개의 노트북에 대한 회고를 작성해보려 한다.

Data Preparation & Exploration
이름에서 볼 수 있듯이 모델링 과정 없이 전처리를 위주로 진행하는 노트북이다.
다음과 같이 feature들은 접두사, 접미사 형태로 구성되어 있으며 개수는 59개로 굉장히 많은 편이다.
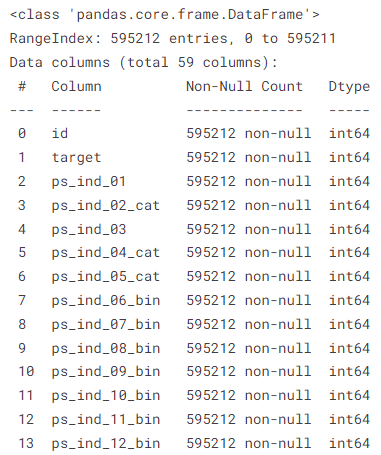

이 변수들을 분석에 용이하게 하기 위해 Metadata를 만든다.
각 feature별 해당 feature가 어떤 역할(role)을 하는지, 어떤 변수(level)인지, 계속해서 사용(keep)할 것인지, 그리고 어떤 데이터 형태(dtype)인지를 나타낸다.
이 메타정보를 활용하여 각 변수별 요약정보를 확인하기도 하고, EDA를 진행하기도 한다.

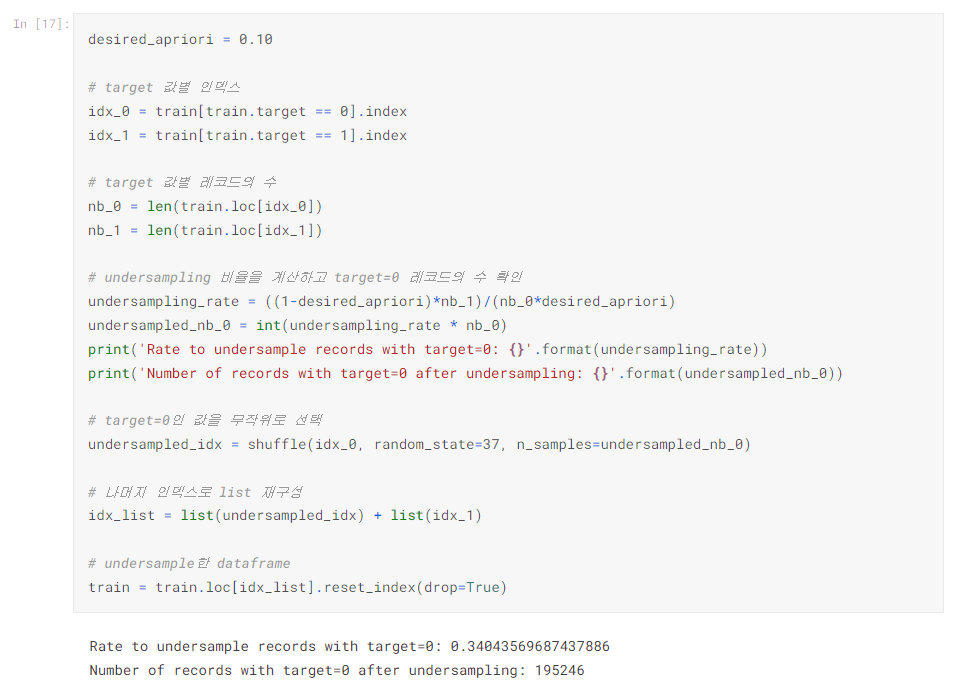
예측 변수인 target의 분포가 불균형하기 때문에 균형을 맞춰줄 필요가 있었다.
이 데이터에서는 1보다 0이 많이 때문에 0을 언더샘플링(undersampling)하거나 1을 오버샘플링(oversampling) 해야 했다.
trainset이 꽤 크기 때문에 target=0인 레코드를 언더샘플링 하였다.
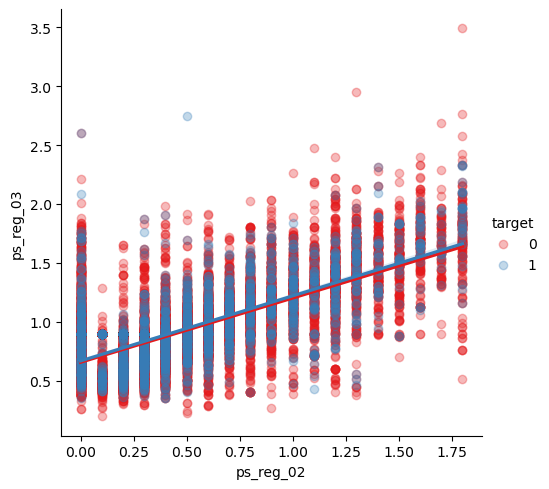
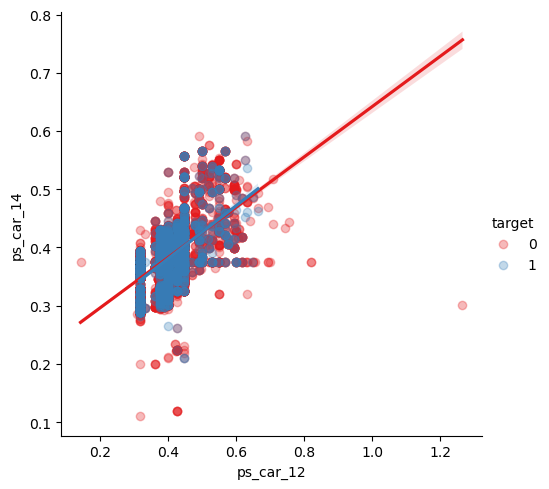
또한, 연속변수들 간의 관계를 파악하였다.
heatmap을 통해 확인했을 때 강한 상관관계를 가지는 두 변수들 간의 관계를 lmplot을 사용하여 시각화하였다.


예측에 사용할 변수를 선택하기 위해 모델을 사용하였다.
앞서, 더미변수를 만들어 총 164개의 feature가 되었고, 이 데이터들 중 분산을 기준으로 1% 미만인 31개의 변수를 제거하였다.
RandomForest의 feature importance를 기준으로 변수를 선택한다.
sklearn의 SelectFromModel을 사용하여 유지할 변수의 개수를 지정할 수 있도록 하였으며, feature importance의 임계값을 상위 50%으로 설정해, 최종적으로 81개의 변수를 선정하였다.
이 노트북에서는 예측 모델을 생성하지는 않았지만, feature scaling을 통해 예측 변수의 성능을 높일 수 있을 것으로 생각된다.
titanic은 ML, DS 입문자라면 모두가 접하는 데이터이다 보니 나 역시도 여러 수업들에서 접해보았기 때문에 데이터를 이해하는데 큰 어려움이 없었다.
하지만 이번 데이터는 처음 보는 데이터였기 때문에 어떤 예측을 위해 사용하는지, 데이터의 컬럼들이 무슨 역할을 하는지 이해하기 어려웠다.
그렇기 때문에 코드를 쓰면서도 이 변수가 뭐였더라? 하는 되새김의 시간이 너무나 많이 필요했고, 처음 작성해 보는 코드들도 많았기 때문에 완료까지 시간이 꽤 소요되었던 것 같다.
흡수하지 못한 것이 많게 느껴져서 다음에 다시 해 볼 계획이다.
GitHub - dduniverse/kaggle-copy
Contribute to dduniverse/kaggle-copy development by creating an account on GitHub.
github.com